Database-like ops benchmark
The code for this benchmark can be found at https://github.com/duckdblabs/db-benchmark and has been forked from https://github.com/h2oai/db-benchmark.
This page aims to benchmark various database-like tools popular in open-source data science. It runs whenever a PR is opened requesting an update, provided the PR author has ran the benchmark themselves. We provide this as a service to both developers of these packages and to users. You can find out more about the project in Efficiency in data processing slides and talk made by Matt Dowle on H2OWorld 2019 NYC conference.
We also include the syntax being timed alongside the timing. This way you can immediately see whether you are doing these tasks or not, and if the timing differences matter to you or not. A 10x difference may be irrelevant if that’s just 1s vs 0.1s on your data size. The intention is that you click the tab for the size of data you have.
Machine Type
Small (16 cores / 32GB memory)
Task
groupby
0.5 GB
basic questions

advanced questions

5 GB
basic questions

advanced questions

50 GB
basic questions

advanced questions

join
0.5 GB
basic questions

5 GB
basic questions

50 GB
basic questions

X-Large (128 cores / 256GB memory)
Task
groupby
0.5 GB
basic questions

advanced questions

5 GB
basic questions

advanced questions
50 GB
basic questions

advanced questions

join
0.5 GB
basic questions

5 GB
basic questions

50 GB
basic questions

Details
groupby
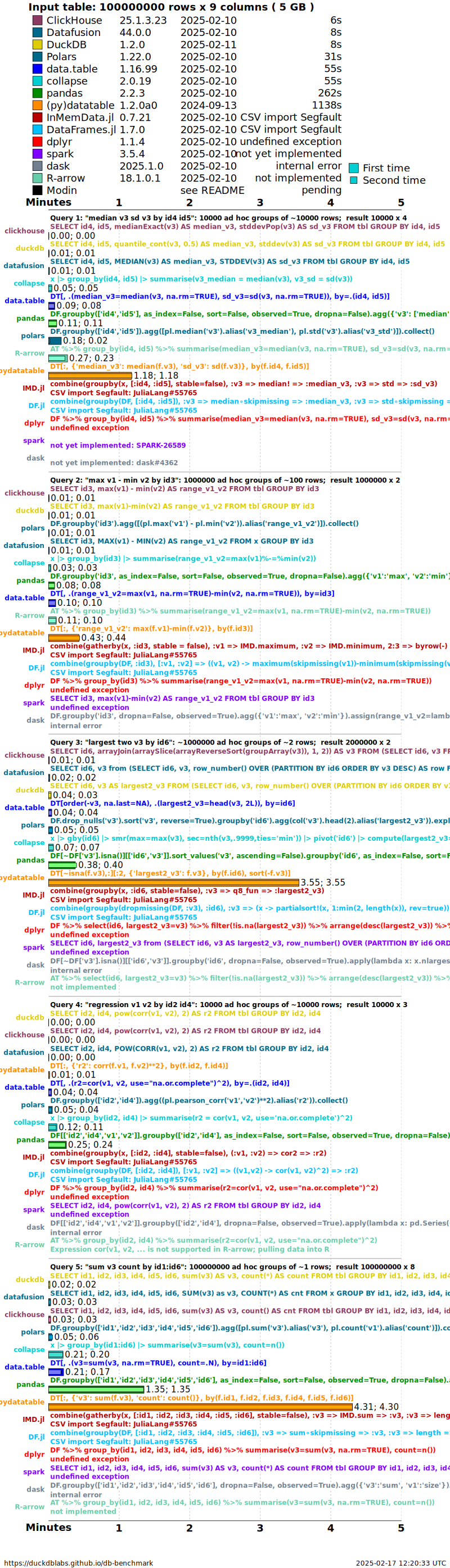
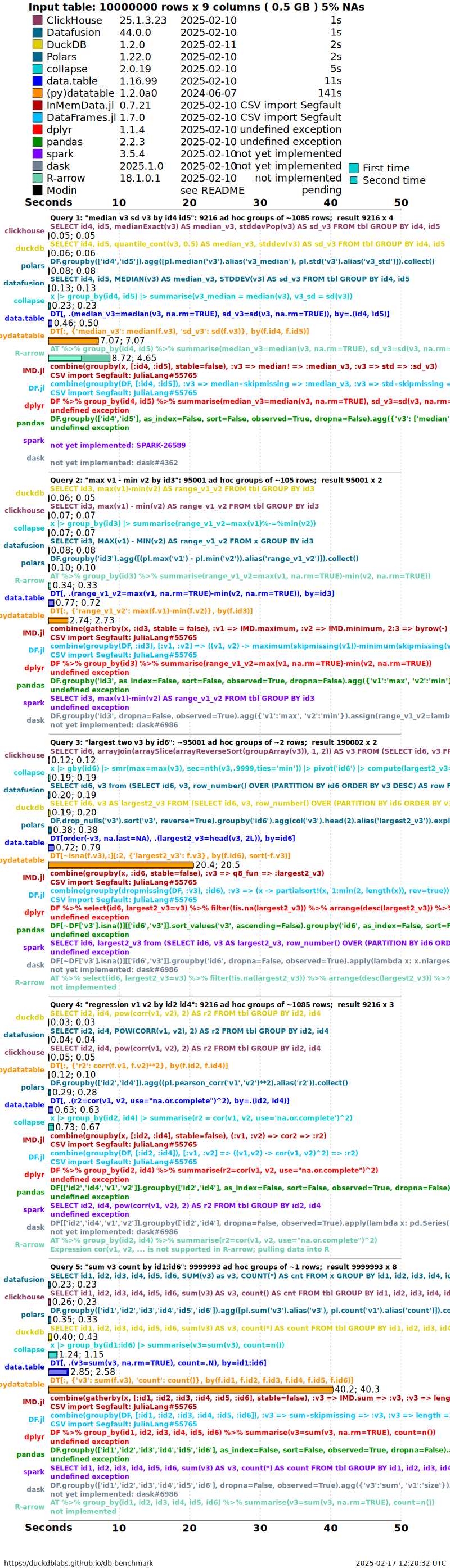
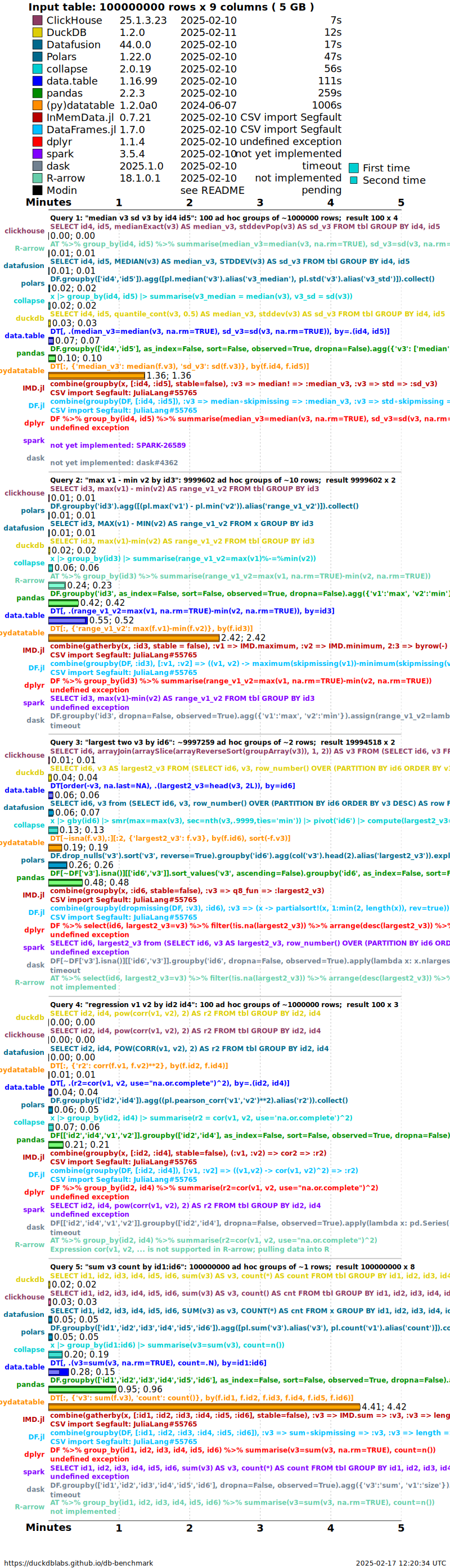
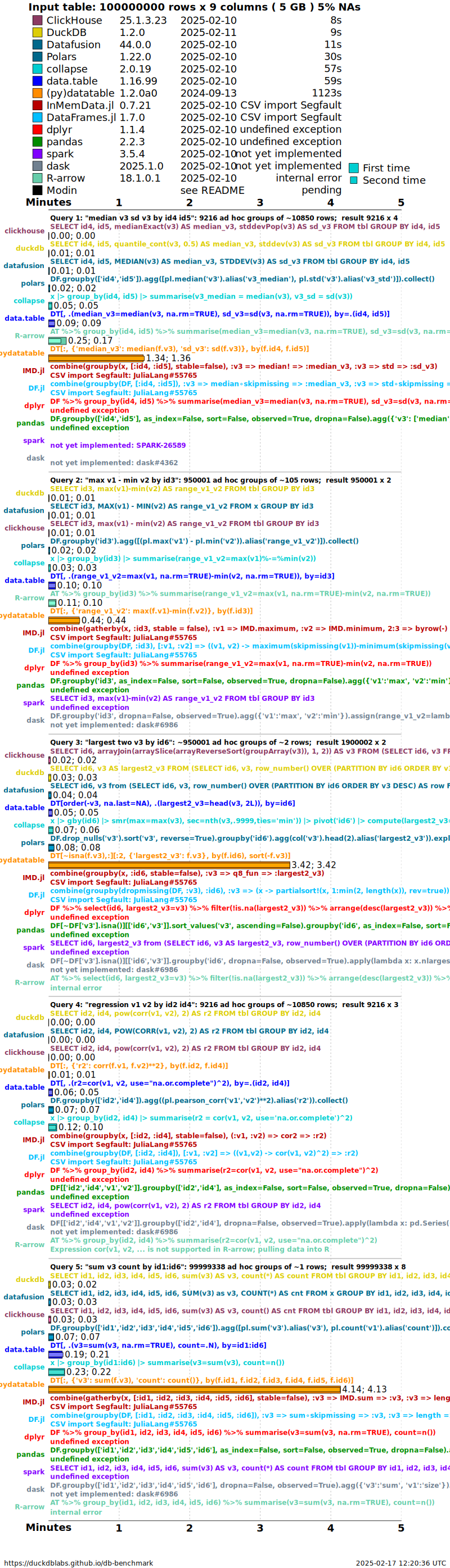
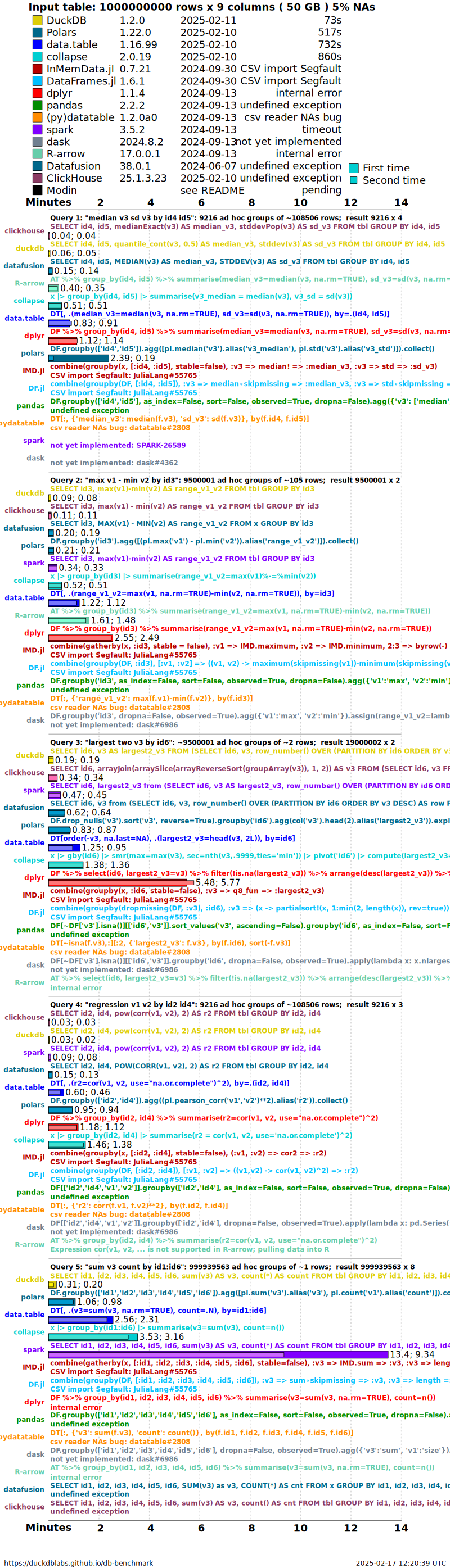
Timings are presented for a single dataset case having random order,
no NAs (missing values) and particular cardinality factor (group size
question 1 k=100). To see timings for other cases go to the
very bottom of this page.
groupby timings
join
Timings are presented for datasets having random order, no NAs (missing values). Data size on tabs corresponds to the LHS dataset of join, while RHS datasets are of the following sizes: small (LHS/1e6), medium (LHS/1e3), big (LHS). Data case having NAs is testing NAs in LHS data only (having NAs on both sides of the join would result in many-to-many join on NA). Data case of sorted datasets tests data sorted by the join columns, in case of LHS these are all three columns id1, id2, id3 in that order.
join timings
Errors
Since adding the new machine type, many updates need to be made to report generation in order to accommodate the extra dimension of the benchmark. One area where this maintenance has not yet occured is with error reporting. Please be patient while this is worked on. Many error “Not Tested” errors are placeholders for “Out of Memory” errors. I can re-run certain benchmarks on request, but please double check that they will not run out of memory. If you see an error that doesn’t make sense and you are sure is not an out of memory error feel free to file an issue.
Requesting an updated run
The benchmark will now be updated with PR requests. To publish new
results for a solution(s), you can open a PR with changes to solutions
scripts or VERSION files, with updates to the time.csv and log.csv files
of a run on a c6id.metal machine or c6id.4xlarge. If using a
c6id.4xlarge, we recommend a dedicated instance, to avoid variable
performance due to noisy neighbors. To facilitate creating an instance
identical to the one with the current results, the script
_setup_utils/mount.sh and
_setup_utils/setup_small were created. The script does the
following
- Formats and mounts an nvme drive so that solutions have access to instance storage. This prevents variability in performance due to network storage.
- Creates a new directory
db-benchmark-metalon the nvme drive. This directory is a clone of the repository
Once the db-benchmark-metal directory is created, you
will need to 1. Install the solutions you wish to have updated 2. Update
the solution(s) groupby or join scripts with any desired changes 3.
Modify the run.conf file so that your desired solution/task is run. 4.
Run the benchmark on your solution by calling _run/partitioned_run.sh
(note this will download the data and then delete it after the run. If
you wish to have the benchmark data persist, comment out the lines
removing the dta.) 5. Generate the report to see how the results compare
to other solutions 6. Create your PR! (make sure the new time.csv and
logs.csv files are included!)
The PR will then be reviewed by the DuckDB Labs team where we will run the benchmark ourselves to validate the new results. If there aren’t any questions, we will merge your PR and publish a new report!
Notes
- You are welcome to run this benchmark yourself! All scripts related
to setting up environment, data and benchmark are in the repository repository in the
_setup_utilsdirectory. Please remember to run_setup_utils/mount.shso you know you are running on the instance storage and not network backed storage. - Data used to generate benchmark plots on this website can be obtained from time.csv (together with logs.csv). See _report/report.R for quick introduction how to work with those. You can also download them from aws s3 without requiring any credentials.
- Solutions are using in-memory data storage to achieve best timing.
In case a solution runs out of memory (for the smaller machine), it will
use nvme storage if correctly set up. In these cases, the solution name
is denoted by a
*suffix on the legend. - ClickHouse and DuckDB queries are
CREATE TABLE ans AS SELECT ...to match the functionality provided by other solutions in terms of caching results of queries, see #151. - We ensure that calculations are not deferred by solution.
- Because of the above, as of current moment, join timings of python datatable suffers from an extra deep copy. As a result of that extra overhead it suffers additionally with out of memory error for 1e9 join q5 big-to-big join.
- We also tested that answers produced from different solutions match each others, for details see _utils/answers-validation.R.
Environment configuration
- R 4.3.2
- python 3.10
- Julia 1.9.3
| Component | Value |
|---|---|
| CPU model | Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz |
| CPU cores | 128 |
| RAM model | NVMe SSD |
| RAM GB | 250 |
| GPU model | None |
| GPU num | None |
| GPU GB | None |
Scope
We limit the scope to what can be achieved on a single machine. Laptop size memory (8GB) and server size memory (250GB) are in scope. Out-of-memory using local disk such as NVMe is in scope. Multi-node systems such as Spark running in single machine mode is in scope, too. Machines are getting bigger: EC2 X1 has 2TB RAM and 1TB NVMe disk is under $300. If you can perform the task on a single machine, then perhaps you should. To our knowledge, nobody has yet compared this software in this way and published results too. Some solutions are not run on smaller machines. You can request a run for your solution, but there is no guarantee when the run will take place.
Why db-benchmark?
Because we have been asked many times to do so, the first task and initial motivation for this page, was to update the benchmark designed and run by Matt Dowle (creator of data.table) in 2014 here. The methodology and reproducible code can be obtained there. Exact code of this report and benchmark script can be found at h2oai/db-benchmark created by Jan Gorecki funded by H2O.ai. H2O.ai stopped supporting the benchmark in 2021. In 2023, DuckDB Labs decided to start maintaining the benchmark, and code can be found at duckdblabs/db-benchmark.
Explore more data cases
| task | in rows | data description | machine type | benchplot |
|---|---|---|---|---|
| groupby | 1e7 | 1e2 cardinality factor, 0% NAs, unsorted data | c6id.metal | basic, advanced |
| groupby | 1e7 | 1e2 cardinality factor, 0% NAs, unsorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e7 | 1e1 cardinality factor, 0% NAs, unsorted data | c6id.metal | basic, advanced |
| groupby | 1e7 | 1e1 cardinality factor, 0% NAs, unsorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e7 | 2e0 cardinality factor, 0% NAs, unsorted data | c6id.metal | basic, advanced |
| groupby | 1e7 | 2e0 cardinality factor, 0% NAs, unsorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e7 | 1e2 cardinality factor, 0% NAs, pre-sorted data | c6id.metal | basic, advanced |
| groupby | 1e7 | 1e2 cardinality factor, 0% NAs, pre-sorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e7 | 1e2 cardinality factor, 5% NAs, unsorted data | c6id.metal | basic, advanced |
| groupby | 1e7 | 1e2 cardinality factor, 5% NAs, unsorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e8 | 1e2 cardinality factor, 0% NAs, unsorted data | c6id.metal | basic, advanced |
| groupby | 1e8 | 1e2 cardinality factor, 0% NAs, unsorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e8 | 1e1 cardinality factor, 0% NAs, unsorted data | c6id.metal | basic, advanced |
| groupby | 1e8 | 1e1 cardinality factor, 0% NAs, unsorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e8 | 2e0 cardinality factor, 0% NAs, unsorted data | c6id.metal | basic, advanced |
| groupby | 1e8 | 2e0 cardinality factor, 0% NAs, unsorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e8 | 1e2 cardinality factor, 0% NAs, pre-sorted data | c6id.metal | basic, advanced |
| groupby | 1e8 | 1e2 cardinality factor, 0% NAs, pre-sorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e8 | 1e2 cardinality factor, 5% NAs, unsorted data | c6id.metal | basic, advanced |
| groupby | 1e8 | 1e2 cardinality factor, 5% NAs, unsorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e9 | 1e2 cardinality factor, 0% NAs, unsorted data | c6id.metal | basic, advanced |
| groupby | 1e9 | 1e2 cardinality factor, 0% NAs, unsorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e9 | 1e1 cardinality factor, 0% NAs, unsorted data | c6id.metal | basic, advanced |
| groupby | 1e9 | 1e1 cardinality factor, 0% NAs, unsorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e9 | 2e0 cardinality factor, 0% NAs, unsorted data | c6id.metal | basic, advanced |
| groupby | 1e9 | 2e0 cardinality factor, 0% NAs, unsorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e9 | 1e2 cardinality factor, 0% NAs, pre-sorted data | c6id.metal | basic, advanced |
| groupby | 1e9 | 1e2 cardinality factor, 0% NAs, pre-sorted data | c6id.4xlarge | basic, advanced |
| groupby | 1e9 | 1e2 cardinality factor, 5% NAs, unsorted data | c6id.metal | basic, advanced |
| groupby | 1e9 | 1e2 cardinality factor, 5% NAs, unsorted data | c6id.4xlarge | basic, advanced |
| join | 1e7 | 0% NAs, unsorted data | c6id.metal | basic |
| join | 1e7 | 0% NAs, unsorted data | c6id.4xlarge | basic |
| join | 1e7 | 5% NAs, unsorted data | c6id.metal | basic |
| join | 1e7 | 5% NAs, unsorted data | c6id.4xlarge | basic |
| join | 1e7 | 0% NAs, pre-sorted data | c6id.metal | basic |
| join | 1e7 | 0% NAs, pre-sorted data | c6id.4xlarge | basic |
| join | 1e8 | 0% NAs, unsorted data | c6id.metal | basic |
| join | 1e8 | 0% NAs, unsorted data | c6id.4xlarge | basic |
| join | 1e8 | 5% NAs, unsorted data | c6id.metal | basic |
| join | 1e8 | 5% NAs, unsorted data | c6id.4xlarge | basic |
| join | 1e8 | 0% NAs, pre-sorted data | c6id.metal | basic |
| join | 1e8 | 0% NAs, pre-sorted data | c6id.4xlarge | basic |
| join | 1e9 | 0% NAs, unsorted data | c6id.metal | basic |
| join | 1e9 | 0% NAs, unsorted data | c6id.4xlarge | basic |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Benchmark run took around 62.7 hours.
Report was generated on: 2025-10-27 10:10:42 UTC.